【Kubernetes】Probeの設定値の設計観点
はじめに
Kubernetesのヘルスチェック機能である3種類のProbeについて、どのような観点で値を設定すべきかを考えてみました。
Probeの基本的な説明は本記事では割愛します。
公式の情報:
Liveness Probe、Readiness ProbeおよびStartup Probeを使用する | Kubernetes
Probeの設定値は、パフォーマンスや異常検知のスピードや精度のトレードオフを考慮して調整すべきです。
各Probeの「設定する目的」「NGになったときの振る舞い」をおさえたうえで、
どのパラメーターをどう調整(値を大きくするor小さくする)すると、どんなリスクがあるか、という観点でまとめてみました。
Liveness Probe
目的
再起動されるまで回復できないような異常な状態を検知し、自動で復旧する
NGになった場合の振る舞い
restartPolicyに従う
設定
| パラメータ | 説明 | 大きくするリスク | 小さくするリスク |
|---|---|---|---|
| initialDelaySeconds | コンテナが起動してから、Liveness Probeが開始されるまでの秒数。 Liveness Probeの開始タイミングはstartupProbeで制御できるので、startupProbeを定義する場合は不要。 |
必要以上に増やしすぎると、起動完了後に異常状態になった場合の検知と復旧が遅れる場合がある | コンテナの起動時間(ProbeがOKで帰ってくるようになるまでの時間)が設定した値を超えた場合、コンテナが起動しきらないまま、再起動がかかり、永遠に起動してこない事象に陥る |
| periodSeconds | Probeが実行される頻度(秒数) | 異常の検知・復旧が遅れる場合がある | リクエスト数が多くなるので、コンテナへの負荷がかかる |
| timeoutSeconds | Probeがタイムアウトになるまでの秒数 | レスポンスに時間がかかりすぎることを異常として検知できない | レスポンス時間の必要分確保されていないと、異常を誤検知してしまう可能性がある |
| failureThreshold | Probeが失敗した場合、KubernetesはfailureThresholdに設定した回数までProbeを試行する。試行回数に到達すると、再起動される | 異常が発生してから再起動までの時間が長くなる | 誤検知により再起動が発動してしまう可能性が上がる |
| successThreshold | 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数 | 異常を誤検知してしまう可能性がある | 異常状態の検知が遅れる可能性がある |
Readiness Probe
目的
トラフィックを処理できない状態(例:依存するリソースの起動を待機している)を検知して、リクエストを一時的に遮断する
NGになった場合の振る舞い
トラフィックの遮断(Service のロードバランシングから切り離される)
設定
| パラメータ | 説明 | 大きくするリスク | 小さくするリスク |
|---|---|---|---|
| initialDelaySeconds | コンテナが起動してから、Readiness Probeが開始されるまでの秒数。 Readiness Probeの開始タイミングはstartupProbeで制御できるので、startupProbeを定義する場合は不要。 |
必要以上に増やしすぎると、起動完了後に異常状態になった場合の検知とトラフィックの遮断が遅れる場合がある | コンテナの起動時間(ProbeがOKで帰ってくるようになるまでの時間)が設定した値を超えた場合、コンテナが起動しきらないまま、再起動がかかり、永遠に起動してこない |
| periodSeconds | Probeが実行される頻度(秒数) | 異常の検知・トラフィックの遮断が遅れる場合がある | リクエスト数が多くなるので、コンテナへの負荷がかかる |
| timeoutSeconds | Probeがタイムアウトになるまでの秒数 | レスポンスに時間がかかりすぎることを異常として検知できない | レスポンス時間の必要分確保されていないと、異常を誤検知してしまう可能性がある |
| failureThreshold | Probeが失敗した場合、KubernetesはfailureThresholdに設定した回数までProbeを試行する。試行回数に到達すると、トラフィックが遮断される | 異常が発生してからトラフィック遮断までの時間が長くなる | 誤検知によりトラフィック遮断が発動してしまう可能性が上がる |
| successThreshold | 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数 | 異常を誤検知してしまう可能性がある | 異常状態の検知が遅れる可能性がある |
Startup Probe
目的
コンテナアプリケーションの起動完了を検知し、Liveness ProbeとReadiness Probeの開始タイミングを制御する。
起動に時間がかかるが、どれくらい時間がかかるか予測できないアプリケーションに対して有効。
NGになった場合の振る舞い
restartPolicyに従う
設定
| パラメータ | 説明 | 大きくするリスク | 小さくするリスク |
|---|---|---|---|
| initialDelaySeconds | コンテナが起動してからstartupProbeが開始されるまでの秒数 | 必要以上に増やしすぎると、Probeの開始が遅れ、起動完了後の異常の検知や再起動やトラフィック遮断が送れる可能性がある | |
| periodSeconds | Probeが実行される頻度(秒数) | startupProbe完了までの時間が必要以上にかかってしまう可能性がある | リクエスト数が多くなるので、コンテナへの負荷がかかる |
| timeoutSeconds | Probeがタイムアウトになるまでの秒数 | レスポンスに時間がかかりすぎている状態で、「起動完了」と判定してしまう | レスポンス時間の必要分確保されていないと、異常を誤検知してしまう可能性がある |
| failureThreshold | Probeが失敗した場合、KubernetesはfailureThresholdに設定した回数までProbeを試行する。試行回数に到達すると、再起動される | (periodSeconds*failureThreshold)秒が想定しうる起動時間より短い場合、永遠に起動してこない | |
| successThreshold | 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数 | 異常を誤検知してしまう可能性がある | 異常状態の検知が遅れる可能性がある |
おわりに
エイヤーで実装しがちですが、異常を検知して自動で復旧するのはKubernetesの強みの一つだと思うので、ちゃんと設計に向きあうことは大事ですね。
解釈が誤ってそうな点があれば随時修正します。
【Apache Kafka】Debezium ConnectorをMSK Connectで試してみた
はじめに
本記事はエーピーコミュニケーションズ Advent Calendar 2021の17日目の記事です。
2021年9月16日にリリースされた、AWSマネージドのKafka Connectクラスター管理機能「MSK Connect」を試してみました。
本記事の検証では、上記の記事を参考に、DBはPostgreSQL(RDSのDBインスタンス)とし、コネクタープラグインはDebezium Postgres Connectorに置き換えています。
2021/12/11時点のAWSマネジメントコンソールから操作しています。
AWSマネジメントコンソールのUIはアップデートされる可能性があります。
環境構築
構成図

1. VPC/Subnet/Bastion(EC2)の作成
本記事では、詳しい作成方法は割愛します。
2. MSKクラスター設定の作成
- AWSマネジメントコンソールのMSKサービスのメニュー「クラスター構成」画面を開く
- 「クラスター設定を作成」を押下
- 「構成名」には任意の文字列、「リビジョン1の設定プロパティ」の以下の部分を修正
auto.create.topics.enable=false=>auto.create.topics.enable=true
- 「作成」を押下
3. MSK/RDS/MSK Connect用リソースの構築
CloudFormationを使用して以下のリソースを作成しました。
- MSK用のSecurityGroup
- MSK Cluster
- DB用のSecurityGroup
- RDS DBインスタンス
- RDS DBサブネットグループ
- RDS DBパラメータグループ
- MSK Connectに設定するIAMロール
- IAMロールにアタッチするIAMポリシー(参考)
- MSK Connectのログを格納するロググループ
以下、使用したCloudFormationテンプレートです。
AWSTemplateFormatVersion: "2010-09-09" Parameters: ClusterName: Type: String Description: MSK Cluster Name DBInstanceIdentifier: Type: String Description: DB Instance Identifier Vpc: Type: AWS::EC2::VPC::Id Description: Target VPC id Subnet1: Type: AWS::EC2::Subnet::Id Description: Target Subnet id Subnet2: Type: AWS::EC2::Subnet::Id Description: Target Subnet id ClientSecurityGroup: Type: AWS::EC2::SecurityGroup::Id Description: Security Group of Client(Bastion) DefaultSecurityGroup: Type: AWS::EC2::SecurityGroup::Id Description: Default Secrity Group of Target VPC MSKConfigurationInfoArn: Type: String Description: Arn of MSK Configration(use resource created in step2) DBUser: Type: String Description: Username of DB Instance DBPassword: Type: String Description: Password of DB Instance user Resources: MSKSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: debezium test SecurityGroupIngress: - SourceSecurityGroupId: !Ref ClientSecurityGroup IpProtocol: tcp ToPort: 9092 FromPort: 9092 - SourceSecurityGroupId: !Ref ClientSecurityGroup IpProtocol: tcp ToPort: 2181 FromPort: 2181 - SourceSecurityGroupId: !Ref ClientSecurityGroup IpProtocol: tcp ToPort: 9098 FromPort: 9098 VpcId: !Ref Vpc MSKCluster: Type: AWS::MSK::Cluster Properties: BrokerNodeGroupInfo: ClientSubnets: - !Ref Subnet1 - !Ref Subnet2 InstanceType: kafka.m5.large SecurityGroups: - !Ref MSKSecurityGroup - !Ref DefaultSecurityGroup StorageInfo: EBSStorageInfo: VolumeSize: 30 ClusterName: !Ref ClusterName ClientAuthentication: Unauthenticated: Enabled: true Sasl: Iam: Enabled: true KafkaVersion: 2.7.1 ConfigurationInfo: Arn: !Ref MSKConfigurationInfoArn Revision: 1 EncryptionInfo: EncryptionInTransit: ClientBroker: TLS_PLAINTEXT InCluster: true EnhancedMonitoring: DEFAULT NumberOfBrokerNodes: 2 DBSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: debezium test SecurityGroupIngress: - SourceSecurityGroupId: !Ref ClientSecurityGroup IpProtocol: tcp ToPort: 5432 FromPort: 5432 VpcId: !Ref Vpc DBInstance: Type: AWS::RDS::DBInstance DeletionPolicy: Delete Properties: DBInstanceIdentifier: !Ref DBInstanceIdentifier DBInstanceClass: db.t3.small DBSubnetGroupName: !Ref DBSubnetGroup AllocatedStorage: 10 Engine: postgres EngineVersion: 13.4 MasterUsername: !Ref DBUser MasterUserPassword: !Ref DBPassword StorageType: gp2 BackupRetentionPeriod: 0 VPCSecurityGroups: - !Ref DBSecurityGroup - !Ref DefaultSecurityGroup DBParameterGroupName: !Ref DBParameterGroup DBSubnetGroup: Type: AWS::RDS::DBSubnetGroup Properties: DBSubnetGroupDescription: subnet group for debezium test SubnetIds: - !Ref Subnet1 - !Ref Subnet2 DBParameterGroup: Type: AWS::RDS::DBParameterGroup Properties: Family: postgres13 Description: for debezium test Parameters: rds.logical_replication: 1 IAMPolicy: Type: AWS::IAM::Policy Properties: PolicyName: msk-connect-role PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - kafka-cluster:Connect - kafka-cluster:DescribeCluster - kafka-cluster:AlterCluster - kafka-cluster:DescribeClusterDynamicConfiguration Resource: - !Ref MSKCluster - Effect: Allow Action: - kafka-cluster:*Topic* - kafka-cluster:ReadData - kafka-cluster:WriteData Resource: - !Sub "arn:aws:kafka:${AWS::Region}:${AWS::AccountId}:topic/${ClusterName}/*" - Effect: Allow Action: - kafka-cluster:AlterGroup - kafka-cluster:DescribeGroup Resource: - !Sub "arn:aws:kafka:${AWS::Region}:${AWS::AccountId}:group/${ClusterName}/*" - Effect: Allow Action: - logs:CreateLogDelivery - logs:PutResourcePolicy - logs:DescribeResourcePolicies - logs:DescribeLogGroups Resource: - !GetAtt LogGroup.Arn Roles: - !Ref IAMRole IAMRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - kafkaconnect.amazonaws.com Action: - sts:AssumeRole Description: for MSK Connect LogGroup: Type: AWS::Logs::LogGroup Properties: RetentionInDays: 7
4. PostgreSQLにデータベース・テーブル作成
BastionからPostgreSQLに接続し、データベース・テーブルを作成します。
Bastionにはpostgresqlをインストールし、psqlコマンドが使用できるようにしておきます。
データベース名はdebezium-testとして作成しました。
- Bastionから以下のコマンドでPostgreSQLに接続
psql -h <DBインスタンスのエンドポイント> -p 5432 -U <DBのユーザー名> -d postgres
- パスワードを入力し、ログインする
- 以下のコマンドでデータベース作成し、接続する
CREATE DATABASE "debezium-test"; \c debezium-test
- 以下のコマンドでテーブル作成
CREATE TABLE users ( id int, name varchar(32) ); ALTER TABLE users REPLICA IDENTITY FULL;
5. MSK Connectの設定
- コネクタプラグイン格納用のS3バケットを事前に準備
- https://debezium.io/releases/ から最新のDebeziumコネクターをダウンロード
- 検証時は1.7.1のPostgres Connector Pluginを使用
- tarコマンド、zipコマンドが使用できる環境で、アップロードするための構成に変更
tar xvf debezium-connector-postgres-1.7.1.Final-plugin.tar.gz cd debezium-connector-postgres zip -9 ../debezium-connector-postgres-1.7.1.zip * cd ..
- debezium-connector-postgres-1.7.1.zipをS3バケットにアップロード
- AWSマネジメントコンソールのMSKサービスのメニュー「コネクタ」画面を開く
- 「コネクタを作成」を押下
- 「カスタムプラグインタイプ」の項目で「カスタムプラグインを作成」を選択
- 「S3 URI - カスタムプラグインオブジェクト」では手順4でアップロードしたzipファイルを設定する
- カスタムプラグイン名を設定して「次へ」を押下
- コネクタのプロパティ画面に遷移するので以下の設定をし、「次へ」を押下
- 基本情報-コネクタ名:任意のコネクター名を設定
- Apache Kafka-クラスタータイプ:MSKクラスター
- CloudFormationで作成したMSKクラスターを選択
- 認証メソッドは「IAM」を選択
- コネクタ設定
connector.class=io.debezium.connector.postgresql.PostgresConnector tasks.max=1 database.hostname=<DBインスタンスのエンドポイント> database.dbname=<データベース名> database.port=5432 database.user=<DBのユーザー名> database.password=<DBのパスワード> database.server.id=123456 database.server.name=debezium-test-db database.history.kafka.bootstrap.servers=<MSKのBootstrapServersのエンドポイント(認証タイプ「IAM」)> database.history.consumer.security.protocol=SASL_SSL database.history.consumer.sasl.mechanism=AWS_MSK_IAM database.history.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; database.history.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler database.history.producer.security.protocol=SASL_SSL database.history.producer.sasl.mechanism=AWS_MSK_IAM database.history.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; database.history.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler include.schema.changes=true plugin.name=pgoutput
- コネクタのキャパシティー:(すべてデフォルト)
- ワーカー設定:MSK のデフォルト設定を使用
- アクセス許可:CloudFormationで作成したIAMロール
- 「次へ」を押下
- ログ配信で「Amazon CloudWatch Logs への配信」を選択
- CloudFormationで作成したロググループを設定し、「次へ」を選択
- 設定内容を確認し、「コネクタを作成」を押下
- コネクタの状態が「Active」になるのを待つ
本検証のコネクタが「Failed」になることがしばしばありました。
なぜFailedになっているのかは、コネクタのログを見ないと推測できないようです。
ログ配信設定は有効にしてお試しすることを推奨します。
(本記事ではCloudWatch Logsを使用してます。)
Kafka Topicの確認
BastionにKafkaクライアントツールをインストールしておきます。
本検証では、v2.8.1を使用しました。
Topicにどんなメッセージが格納されるのか確認します。
以下のコマンドでTopic一覧を確認します。
<Kafkaクライアントツールインストールパス>/bin/kafka-topic.sh --list --zookeeper <MSKクラスターのzookeeperのエンドポイント>
DBに何も操作をしていない時点では、以下のTopicが存在します。
__amazon_msk_connect_*はコネクタによって自動的に作成されたTopicです。
__amazon_msk_canary __amazon_msk_connect_configs_debezium-test_067bcbed-2e35-492b-8c4c-84ff98c90bcc-4 __amazon_msk_connect_offsets_debezium-test_067bcbed-2e35-492b-8c4c-84ff98c90bcc-4 __amazon_msk_connect_status_debezium-test_067bcbed-2e35-492b-8c4c-84ff98c90bcc-4 __consumer_offsets
INSERT文
試しに適当なINSERT文を実行します。
INSERT INTO users VALUES(1,'piyomaru');
DB操作を行った後、Topic一覧を確認すると、
debezium-test-db.public.usersというTopicが自動的に生成されていました。
以下のコマンドで、Topicのメッセージを確認します。
<Kafkaクライアントツールインストールパス>/bin/kafka-console-consumer.sh --bootstrap-server <MSKクラスターのBootstrap Serverのエンドポイント> --topic <Topic名> --from-beginning
以下のメッセージが格納されていました。
Struct{after=Struct{id=1,name=piyomaru},source=Struct{version=1.7.1.Final,connector=postgresql,name=debezium-test-db,ts_ms=1639304674844,db=debezium-test,sequence=["1207988808","1275070024"],schema=public,table=users,txId=597,lsn=1275070024},op=c,ts_ms=1639304675254}
他にも実行してみます。
UPDATE文
UPDATE users SET name="Piyomaru" WHERE id=1;
メッセージ
Struct{before=Struct{id=1,name=piyomaru},after=Struct{id=1,name=Piyomaru},source=Struct{version=1.7.1.Final,connector=postgresql,name=debezium-test-db,ts_ms=1639305735822,db=debezium-test,sequence=["1543504608","1543505184"],schema=public,table=users,txId=603,lsn=1543505184},op=u,ts_ms=1639305736034}
DELETE文
DELETE FROM users WHERE id=2;
メッセージ
Struct{before=Struct{id=2,name=piyokichi},source=Struct{version=1.7.1.Final,connector=postgresql,name=debezium-test-db,ts_ms=1639305770016,db=debezium-test,sequence=["1543505456","1543505512"],schema=public,table=users,txId=604,lsn=1543505512},op=d,ts_ms=1639305770418}
DBの操作をTopicに格納できていることが確認できました。
おわりに
マイクロサービスが個別にDBを持つ構成の場合に、Kafka、Kafka Connect(Debezium Connector)を活用することで、各DB間の整合性を保つ仕組みを構築することができるようです。(以下、参考記事)
今回の検証ではここまでできませんでしたが、とても興味深いので、別の機会に検証したいと考えてます。
今年はKafka漬けの一年でした。少し仲良くなれたと思います。
よいお年を!
参考
【Apache Kafka】Mirror Maker2でKafkaクラスターをレプリケーション
はじめに
Apache KafkaクラスターのレプリケーションツールMirror Maker2を触ってみました。
今回の検証ではActive/Stanbyの構成を想定しています。
実行手順と気づいた注意点を記載します。
実行環境
Apache Kafka動作環境
※ベストプラクティスでは、Mirror Maker2はセカンダリークラスター側で動作させることを推奨しています。
※使用サービスが異なるのは、深い意味はないです。(MSKの検証してた名残です)
※本手順はMSK to MSK(Mirror Maker2は別途EC2で動作)/ MSK to EC2 / EC2 to EC2でも応用できると思います。
※バージョンが異なるのも深い意味はないです。(後から気づいた)
Producer/Consumerアプリケーション
検証には自作のquorkusアプリケーションを使用しています。
Producer/ConsumerともにEKS上のDeploymentとして起動させています。
本題ではないので詳細は割愛しますが、概要は以下の通りです。
- Producer
- HTTPリクエストのPOSTメソッドで送信されたデータをKafkaのmessagesトピックに格納する
- Consumer
- Kafkaのmessagesトピックに格納されたデータを受信しログに出力する
※アプリケーションは環境変数でKafkaの向き先を切り替えられるように仕込んであります。
Mirror Maker2実行手順
※本手順の前提として、Mirror Maker2実行環境のKafkaインストールパスはKAFKA_PATHと表現します。
1. 設定ファイル
- KAFKA_PATH/config/connect-mirror-maker.properties
# Licensed to the Apache Software Foundation (ASF) under A or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see org.apache.kafka.clients.consumer.ConsumerConfig for more details # Sample MirrorMaker 2.0 top-level configuration file # Run with ./bin/connect-mirror-maker.sh connect-mirror-maker.properties # specify any number of cluster aliases clusters = primary, secondary # connection information for each cluster # This is a comma separated host:port pairs for each cluster # for e.g. "A_host1:9092, A_host2:9092, A_host3:9092" primary.bootstrap.servers = localhost:9092 secondary.bootstrap.servers = b-1.msk-cluster-name.xxxxxx.kafka.ap-northeast-1.amazonaws.com:9092,msk-cluster-name.xxxxxx.kafka.ap-northeast-1.amazonaws.com:9092 # enable and configure individual replication flows primary->secondary.enabled = true # regex which defines which topics gets replicated. For eg "foo-.*" primary->secondary.topics = .* secondary->primary.enabled = false secondary->primary.topics = .* # Setting replication factor of newly created remote topics replication.factor=2 ############################# Internal Topic Settings ############################# # The replication factor for mm2 internal topics "heartbeats", "B.checkpoints.internal" and # "mm2-offset-syncs.B.internal" # For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3. primary.checkpoints.topic.replication.factor=1 primary.heartbeats.topic.replication.factor=1 primary.offset-syncs.topic.replication.factor=1 # The replication factor for connect internal topics "mm2-configs.B.internal", "mm2-offsets.B.internal" and # "mm2-status.B.internal" # For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3. primary.offset.storage.replication.factor=1 primary.status.storage.replication.factor=1 primary.config.storage.replication.factor=1 secondary.offset.storage.replication.factor=2 secondary.status.storage.replication.factor=2 secondary.config.storage.replication.factor=2 # customize as needed # replication.policy.separator = _ # sync.topic.acls.enabled = false # emit.heartbeats.interval.seconds = 5 primary->secondary.sync.group.offsets.enabled = true
ポイント
primary->secondary.enabled = trueとsecondary->primary.enabled = falseと設定することで、トピックの同期は、プライマリークラスターからセカンダリークラスターの一方向のみで実施されます。セカンダリクラスターからプライマリークラスターには同期されません。- Active/Active構成の場合は、
primary->secondary.enabled = trueとsecondary->primary.enabled = trueとします。
- Active/Active構成の場合は、
- 移行先(MSK)には
(移行元論理名).(トピック名)のトピックが自動的に作成されます。- セパレーターはデフォルトで
.ですが、replication.policy.separatorでカスタム可能です。
- セパレーターはデフォルトで
*.replication.factorに設定する数字は、ブローカー台数と合わせます。- 移行元と移行先のブローカー台数が一致する場合は設定はまとめられます。
offset.storage.replication.factor=nのように定義します。
- 移行元と移行先のブローカー台数が異なる場合は、それぞれに設定する必要があるようです。
- 今回は異なるので、
(論理名).offset.storage.replication.factor=nのように記述しています。
- 今回は異なるので、
- 移行元と移行先のブローカー台数が一致する場合は設定はまとめられます。
primary->secondary.sync.group.offsets.enabled = trueを設定することで、オフセット(Consumerがどのメッセージまで読み込んだか)の情報も同期されます。- 2.7.0はデフォルトは
falseのため、明示的に設定が必要です。2.8.0はデフォルトがtrueになっています。 - KIP-545: support automated consumer offset sync across clusters in MM 2.0 - Apache Kafka - Apache Software Foundation
- 2.7.0はデフォルトは
2. Producer/Consumerアプリケーション起動
Kafkaの向き先をプライマリークラスターに設定してProducer/Consumerアプリケーションを起動します。
3. メッセージ発行シェルスクリプト実行
以下のシェルスクリプトを実行し、Producerアプリケーションに対して、HTTPリクエストで毎秒データをPOSTします。
送信したデータはsend_message.logに追記されるようにしています。
#!/bin/bash
url=http://(ProducerアプリケーションのURL):8080
message=`date`
curl --header "Content-Type: text/plain" --request POST --data "$[start] {message}" ${url}
while true; do
message=`date`
echo "${message}" >> send_message.log
curl --header "Content-Type: text/plain" --request POST --data "${message}" ${url}
sleep 1
done
4. Mirror Maker2実行
以下のコマンドでMirror Maker2を実行します。
KAFKA_URL/bin/connect-mirror-maker.sh kafka_2.13-2.7.0/config/connect-mirror-maker.properties
5. ProducerアプリケーションのKafkaの向き先をセカンダリークラスターに変更
マニフェストファイルのKafkaのブローカーを指定している環境変数の値を修正します。
マニフェストファイルをkubectl apply -f (マニフェストファイル名)で読み込み、アプリケーションをデプロイします。
6. ConsumerアプリケーションのKafkaの向き先をセカンダリークラスターに変更
起動しているConsumerアプリケーションのログ出力が止まったら、
マニフェストファイルのKafkaのブローカーを指定している環境変数の値を修正します。
マニフェストファイルをkubectl apply -f (マニフェストファイル名)で読み込み、アプリケーションをデプロイします。
7. 送信データと受信データの確認
送信データ(send_message.log)と受信データ(Consumerコンテナログ出力)を確認します。
データを欠損させないための注意点
Consumerアプリケーション側の設定
Kafkaの向き先変更後の
auto.offset.resetの設定をnoneとします。- デフォルト設定の
latestになっていると、移行先のKafkaからのメッセージ読み出し時点でオフセットはリセットされます。 - 参考:Apache Kafka
- デフォルト設定の
consumer groupを定義します。
- Consumer Groupが定義されていないと、Consumer Group IDはランダムな文字列が割り当てられるため、Kafka自身が、Kafkaの向き先を変える前後で別物のアプリケーションと認識するため、オフセット情報が引き継がれません
Mirror Maker2側の設定
sync.group.offsets.enabledを有効化します。(前述)
データを重複させないための注意点
※検証結果からの推測です。情報の確度は低いですが参考までに。
ConsumerアプリケーションのKafka向き先変更タイミング
ProducerアプリケーションとConsumerアプリケーションをほぼ同時にKafkaの向き先を変えてみたところ、
Consumerが受信したデータが重複していました。
おそらく、移行先KafkaにOffset情報が同期される前に、Consumerがメッセージの消費を開始したためだと思われます。
おわりに
Kafkaに集約するデータの欠損/重複を許容できるかは、システムの性格に依存すると思います。
要件に応じて参考にしていただければ幸いです。
参考
【AWX】GitHubとAWSと連携して、ハンズオン環境をCI/CDする
本記事はエーピーコミュニケーションズ Advent Calendar 2020の12日目の記事です。
はじめに
AWS上のハンズオン環境(使い捨て)をCI/CDする仕組みをAWXとGitHubを連携させて実現してみました。
本記事では、その仕組みの構築方法・運用方法を紹介します。
ハンズオンの内容は、Amazon EC2上で行うAnsible研修を想定しています。
研修内容は他のテーマでも応用可能だと思います。
導入前の課題
本記事で紹介する仕組みは以下のような課題の解決を試みています。
- 以下の手動作業に時間がかかっている
- 研修で使用するハンズオン環境の準備・片付け
- 受講者からの要望を反映した研修内容の実機検証
- 作業ミスによって、同じ環境が再現されないことがある
構成
全体構成は以下のようになります。

※役割について補足
- メンテナンス担当:研修内容・ハンズオン環境のアップデート担当
- オペレーター:研修で使用するハンズオン環境の準備・片付け担当
環境構築
仕組みの構築方法を説明します。
環境情報
2020/11/23に検証しています。
- AWXサーバー
| 項目 | バージョン |
|---|---|
| Instance Type | t2.medium |
| OS | Amazon Linux2 |
| Ansible | 2.9.15 |
| AWX | 15.0.1 |
事前準備
以下のAWSリソースは事前に作成してある想定です。
Playbook作成
以下の用途のroleとそれをキックするPlaybookを作成し、GitHubリポジトリに登録します。
検証で使用したPlaybookを以下のリポジトリに格納してます。
コントロールノードのみの省エネサンプルですが、ご容赦ください。
また、以下の点は検証時に実際に使った時の状態から修正しています。
- ハンズオンのサンプルPlaybook
- 実際は自社研修で使ってるもので検証しましたが、簡易化しています。
- AWSのリソースID
- <XXXのid>みたいな書き方に直してます。
各Playbookの概要を簡単に説明します。
| Playbook名 | 処理内容 | 呼び出すロール |
|---|---|---|
| create_env.yml | CloudformationでEC2インスタンスのスタックを作成 | create_ec2instance |
| setup_env.yml | ハンズオンで使用する教材(サンプルPlaybook)を配置 | setup_master |
| test_scenario.yml | ハンズオンのシナリオを実行する | handson_scenario |
| delete_env.yml | CloudformationでEC2インスタンスのスタックを削除 | delete_ec2instance |
構文チェックをGitHub Actionに設定
developブランチへのPushをトリガーにSyntax CheckとAnsible-Lintを実行するGitHub Action定義を仕込みます。
以下のワークフロー定義ファイルを.github/workflow/ansible-lint.ymlに登録します。
# This is a basic workflow to help you get started with Actions name: CI # Controls when the action will run. on: push: branches: [ develop ] # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: test: runs-on: ubuntu-latest steps: - name: Check out uses: actions/checkout@v2 - name: Set up Python uses: actions/setup-python@v2 - name: Install dependencies run: | python -m pip install --upgrade pip pip install ansible==2.9.15 ansible-lint==4.3 - name: Ansible-Lint run: | ansible-playbook create_env.yml --syntax-check ansible-playbook setup_env.yml --syntax-check ansible-playbook test_scenario.yml --syntax-check ansible-playbook delete_env.yml --syntax-check ansible-lint -x 301 -x 305 --force-color
NGだと以下のように表示されます。
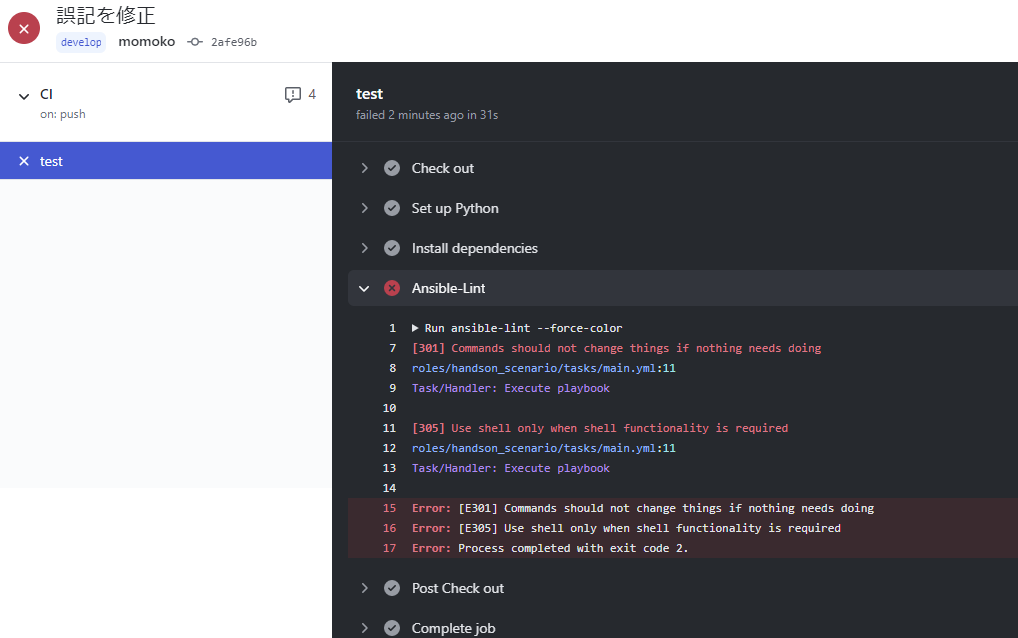
ansible-lint -x 301 -x 305 --force-colorのところを
ansible-lint --force-color(除外ルールなし)で実行してみたら、この結果になりました。
上記、shellモジュール回りで怒られていますが、
shellモジュールの使用は今回のPlaybookはやむを得ないので、
ルールを除外させるようにしてます。
AWX構築
自動テストはAWXから実行させるので、AWXを構築します。
以下のコマンドを順次実行して、AWXをインストールしました。
$ sudo yum update -y $ sudo yum install -y git $ sudo yum install -y docker $ sudo systemctl start docker $ sudo systemctl enable docker $ sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm $ sudo yum --enablerepo=epel install -y ansible $ sudo yum install -y python3 $ sudo pip3 install docker $ sudo pip3 install docker-compose $ git clone https://github.com/ansible/awx $ cd awx/installer/ $ sudo ansible-playbook -i inventory install.yml
http://AWX構築ホストのPublicIP/にアクセスすると、AWXログイン画面が表示されます。
 以下の情報ででログインします。
以下の情報ででログインします。
| ユーザー名 | パスワード |
|---|---|
| admin | password |
また、AnsibleのCloudformationモジュールを使用するために必要なPythonモジュールをインストールします。
$ sudo yum install -y python-pip $ sudo pip install boto3 $ sudo pip install botocore
AWX設定
1.認証情報登録
メニューの認証情報を選択し、+ボタンをクリックして、以下の情報を登録します。
GitHub認証情報
項目 値 名前 github-auth 説明 GitHubリポジトリにアクセスするための認証情報 組織 Default 認証情報タイプ ソースコントロール ユーザ名 (GitHubのユーザ名) パスワード (GitHubのパスワード) AWS認証情報
項目 値 名前 aws-auth 説明 AWS上のインベントリ情報を取得するためのAWS認証情報 組織 Default 認証情報タイプ Amazon Web Service アクセスキー (IAMユーザのアクセスキー) シークレットキー (IAMユーザのシークレットキー) EC2インスタンス認証情報
項目 値 名前 ec2-auth 説明 EC2インスタンスへ接続するための認証情報 組織 Default 認証情報タイプ マシン ユーザー名 ec2-user SSH秘密鍵 (秘密鍵をドラッグアンドドロップ)
2.プロジェクト作成
メニューのプロジェクトを選択し、+ボタンをクリックして、以下の情報を登録します。
| 項目 | 値 |
|---|---|
| 名前 | Hanson-Env |
| 説明 | ハンズオン環境構築コード |
| 組織 | Default |
| SCMタイプ | Git |
| SCM URL | (環境構築コードを登録しているGitHubリポジトリ) |
| SCM認証情報 | github-auth |
3. インベントリ登録
メニューのインベントリーを選択し、+ボタンをクリックして、以下の情報を登録します。
ローカルホスト(Cloudformationモジュール実行対象)
項目 値 名前 localhost ホスト
項目 値 ホスト名 localhost 変数 ansible_connection: local
ansible_python_interpreter: '{{ ansible_playbook_python }}'
-
項目 値 名前 EC2Instances ソース
項目 値 名前 EC2Instances ソース Amazon EC2 認証情報 aws-auth 有効な変数 tags.Name 有効な値 Ansible-Master 上書き ☑ 起動時の更新 ☑
4.ジョブテンプレート登録
メニューのテンプレートを選択し、+ボタン・ジョブテンプレートをクリックして、以下の情報を登録します。
EC2インスタンス作成
項目 値 名前 Create_EC2Instances ジョブタイプ 実行 インベントリー localhost プロジェクト Handson-Env Playbook create_env.yml 認証情報 aws-auth ハンズオン環境セットアップ
項目 値 名前 Setup-Handson ジョブタイプ 実行 インベントリー EC2Instances プロジェクト Handson-Env Playbook setup_env.yml 認証情報 ec2-auth ハンズオンシナリオテスト
項目 値 名前 Test-HandsonScenario ジョブタイプ 実行 インベントリー EC2Instances プロジェクト Handson-Env Playbook test_scenario.yml 認証情報 ec2-auth EC2インスタンス削除
項目 値 名前 Delete_EC2Instances ジョブタイプ 実行 インベントリー localhost プロジェクト Handson-Env Playbook delete_env.yml 認証情報 aws-auth
5.ワークフローテンプレート登録
メニューのテンプレートを選択し、+ボタン・ワークフローテンプレートをクリックして、以下の情報を登録します。
自動テスト
項目 値 名前 自動テスト SCMブランチ develop 
- テスト実行後に確実にEC2インスタンスが削除されるように、以下の分岐条件を仕込みます。
- Setup-Handsonが失敗した場合は、Delete_EC2Instancesに進む
- Test-HandsonScenario実行後は常時(=ジョブテンプレートの成功・失敗に関わらず)Delete_EC2Instancesに進む
- テスト実行後に確実にEC2インスタンスが削除されるように、以下の分岐条件を仕込みます。
ハンズオン環境作成
項目 値 名前 ハンズオン環境作成 SCMブランチ main 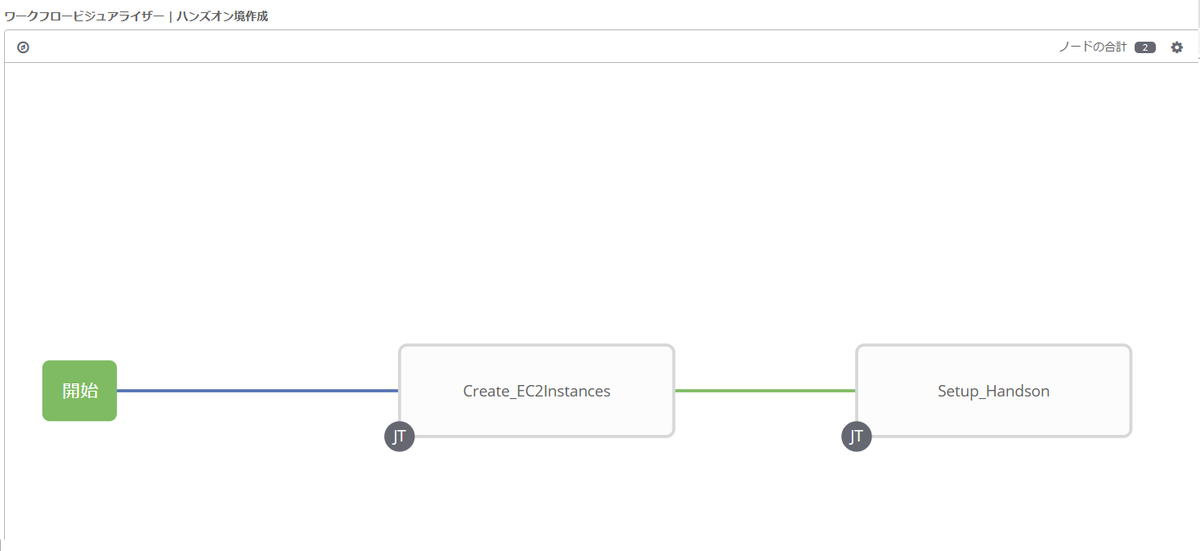
SURVEYの追加
項目 値 プロンプト Number of handson environment 説明 構築するハンズオン環境の台数 回答の変数名 howmany 回答タイプ 整数 最小 1 最大 (受講者の最大数) デフォルトの応答 必須 ☑ SURVEYを設定することによって、ワークフローテンプレート起動時に、
以下のように構築する環境の数を設定できます。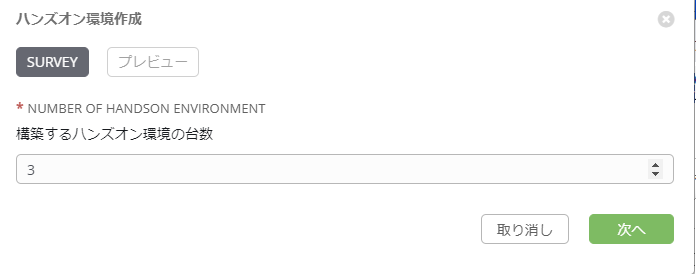
ハンズオン環境削除
項目 値 名前 ハンズオン環境削除 SCMブランチ main 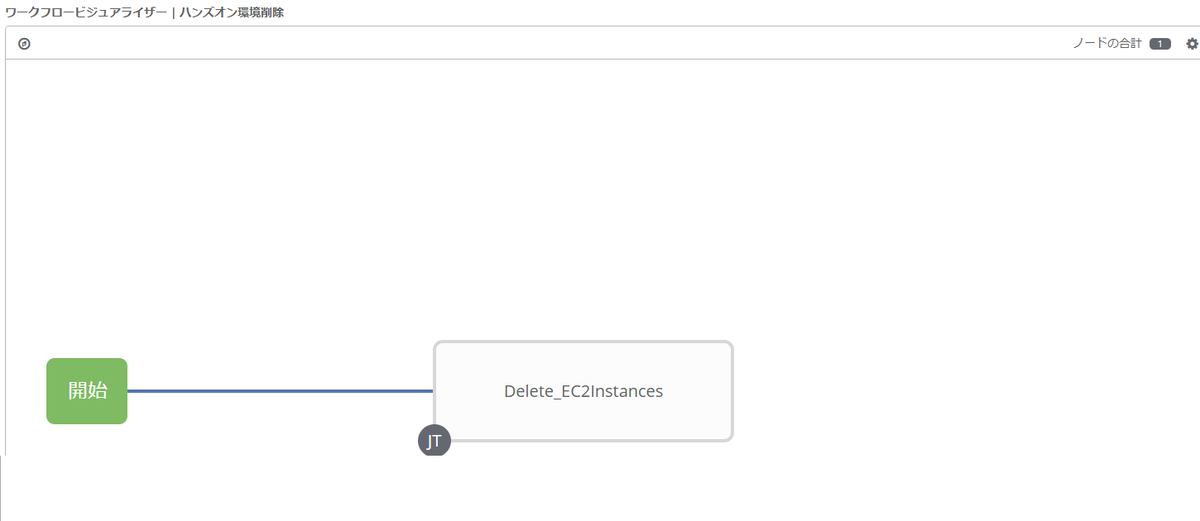
SURVEYの追加
項目 値 プロンプト Number of handson environment 説明 削除するハンズオン環境の台数 回答の変数名 howmany 回答タイプ 整数 最小 1 最大 (受講者の最大数) デフォルトの応答 必須 ☑
権限設定
オペレーター用のユーザーoperationを作ります。
メニューのユーザーを選択し、+ボタンをクリックして、以下の情報を登録します。
| 項目 | 値 |
|---|---|
| ユーザー名 | operation |
| メール | (メールアドレス) |
| ユーザータイプ | 標準ユーザー |
以下のワークフローテンプレートの実行権限のみを持つように設定します。
メニューのテンプレートを選択し、ワークフローテンプレート名をクリックします。
- ハンズオン環境作成
- ハンズオン環境削除
パーミッションタブを選択し、+ボタンをクリックして、以下の情報を登録します。
| 項目 | 値 |
|---|---|
| ユーザ名 | operation |
| ロール | 実行 |
operationユーザでログインすると、テンプレート一覧は以下のように表示されます。

運用方法
以下のような手順で運用される想定です。
更新内容はあくまでも一例です。
トリガー
- 以下の要求が発生
- サンプルPlaybookの改善要望
- 最新バージョンのAnsibleでハンズオンを実施したい

Plan
- 以下の方針で更新することに決定
- サンプルPlaybookを更新する
- Ansibleバージョンを最新化する
Do
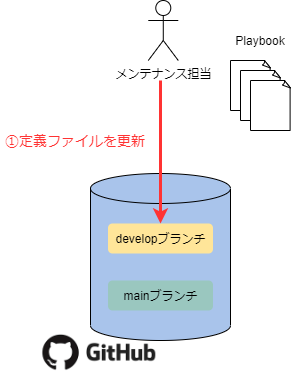
- メンテナンス担当はHandson-Envリポジトリのdevelopブランチで以下を対応
- サンプルPlaybookの更新
- Ansibleバージョン定義部分を更新
Check
- 構文チェック

- 自動テスト
- メンテナンス担当はワークフローテンプレート
自動テストを実行- developブランチの定義ファイルに基づいて以下の処理を自動実行
- ハンズオン環境を自動構築
- 構築したハンズオン環境に、ハンズオンシナリオを実行
- ハンズオン環境を削除
- developブランチの定義ファイルに基づいて以下の処理を自動実行
- メンテナンス担当はワークフローテンプレート

Action
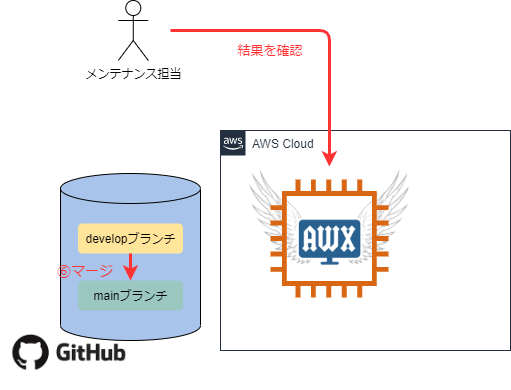
- 自動テストの結果を確認し、問題なければmainブランチにマージ・正式版としてタグ付け
Delivery
- オペレーターはワークフローテンプレート
ハンズオン環境作成を実行- mainブランチの定義ファイルに基づいて、ハンズオン環境を構築
- 研修実施後、オペレーターはワークフローテンプレート
ハンズオン環境削除を実行- mainブランチの定義ファイルに基づいて、ハンズオン環境を削除

仕組み導入後の課題の解決状況
研修で使用するハンズオン環境の準備・片付け
- オペレーターはワンクリックで最新化されたハンズオン環境を受講者の台数分構築できる
- オペレーターはワンクリックで受講者のハンズオン環境を削除できる
受講者からの要望を反映した研修内容の実機検証
- メンテナンス担当は、ワンクリックで以下の項目を確認できる
- 更新した定義ファイルでハンズオン環境が構築できるか
- ハンズオン環境で更新したシナリオが実行できるか
- メンテナンス担当は、ワンクリックで以下の項目を確認できる
- 手動作業による構築のため、作業ミスによって、同じ環境が再現されないことがある
- 定義ファイルはGitで管理するので、検証済みの環境が確実に構築できる
今回の検証でできなかったこと
自動テストの実行トリガーをWebhookにする
もう一つブランチがある想定ですが、
特定のブランチへのマージをトリガーに自動テストが実行されるとか仕込んでみたかったんですが、
時間切れで挫折しました。次の機会に挑戦します。生成されるEC2インスタンスのNameタグを連番にする
今回完成したものは、生成されるEC2インスタンスのNameタグはすべて
Ansible-Masterになっています。
これをAnsible-Master01のように連番にしようと、以下のように試していました。- CloudformationのEC2定義ファイルに生成されるEC2インスタンス共通のタグ
Handson: masterを定義 - インスタンスの
EC2Instancesのソースの有効な変数にtags.Handson、有効な値にmasterを定義
しかし、この設定だと、対象のEC2インスタンスが絞れず、
AWXサーバーもEC2Instancesに含まれてしまいました。
Nameタグだと絞れるのですが、それ以外のタグだと絞れないようです。
回避方法は時間切れで挫折、妥協案でNameタグを統一することにしました。
2021/02/27追記
上記打消し線の事象はAWX17.0.1では解消されていました。
Nameタグ以外のタグでも絞れるようになってます。
バグだったのかな。。- CloudformationのEC2定義ファイルに生成されるEC2インスタンス共通のタグ
おわりに
少々課題が残りましたが、
Git連携・AWS連携・SURVEY・ユーザー権限の設定など、
AWXの機能を活かした検証ができたので、楽しかったです。
参考
Playbook作成
構文チェック関連
AWX
考え方など
【Ansible】Playbookのテストコードサンプル集
はじめに
前回の記事で、Ansibleロール単体テストツール「Molecule」を触ってみたんですけど、
Playbookのテストコードを書くのは初めてだったので、
ちょっと苦労しました。
果たして美しいテストコードかどうかは置いておいて、
Playbookのテストコードのサンプルをメモとして残しておこうと思います。
前提
Ansibleのバージョンは2.9です。
Moleculeで使う前提なので、以下の記述に続く例として書いてます。
--- - name: Verify hosts: all tasks: - name: タスク名 #後述する例です
ファイルの存在チェック(例:/etc/httpd/conf/httpd.conf)
- name: Check that httpd.conf exists stat: path: /etc/httpd/conf/httpd.conf register: result - name: Fail when httpd.conf is not exists fail: msg: "httpd.conf is not exists" when: not result.stat.exists
ファイルの内容チェック(例:/etc/httpd/conf/httpd.confにServerRoot /etc/httpdが設定されているか)
- name: Verify contents in httpd.conf wait_for: path: /etc/httpd/conf/httpd.conf search_regex: "{{ item }}" timeout: 5 with_items: - '^ServerRoot /etc/httpd$' # 検索したい文字列を配列で列挙
パッケージのインストールチェック(例:httpd)
- name: Check yum list shell: yum list installed | grep httpd register: result - name: Check httpd is installed fail: msg: "httpd is not exists" when: result.rc != 0
サービスの起動チェック(例:httpd)
- name: Check Started httpd service: name: httpd state: started check_mode: true register: status_change - name: Fail when httpd is inactive fail: msg: "not started httpd." when: status_change.changed|bool
おわりに
もっといい書き方とか、実はこれはアカンかったとかあれば、
随時更新していこうかと思います。
参考
書籍:インフラCI実践ガイド Ansible/GitLabを使ったインフラ改善サイクルの実現 | 中島 倫明, 佐々木 健太郎, 北山 晋吾, 齊藤 秀喜, 羽深 修 |本 | 通販 | Amazon
【Ansible】Ansibleロール単体テストツールMoleculeを触ってみた
はじめに
AnsibleロールをテストするツールMoleculeを試してみました。
参考:公式ドキュメント
ついでにJenkins+Gitと連携させて、
インフラCIのパイプラインに乗っかる感じで使ってみました。
前提
- Jenkinsマスター・Jenkinsスレーブ・GitLabはDockerコンテナ
- PlaybookのテストはCentos8のDockerコンテナで実行させる
- JenkinsスレーブにDockerをインストール
- ホストOSのdocker daemonを共有させているので、Dockerコンテナが立ち上がるのは、ホストOS上(Not Docker in Docker)
- テストコードもPlaybookで記述
- PlaybookはGitLabの
sample_playbookリポジトリに格納
環境構成
構成図

バージョン情報
| 項目 | 値 |
|---|---|
| Ansible | 2.9.0 |
| Molecule | 3.0.5 |
| ansible-lint | 4.2.0 |
| Docker | 18.09.8-ce |
| Jenkins | 2.176.1 |
| Jenkins Remoting | 3.29 |
| Git | 2.22.4 |
シナリオ
- Ansibleロールを作成
- Ansibleロールを単体テストするPlaybookを作成
- GitにPushする
- Jenkinsジョブ実行
- moleculeテスト結果出力
3→4とか自動化したいとこですが、
そこまではやってません。
Ansibleロール作成
下記のコマンドでmolecule設定ファイルを含んだロールが生成されます。
moecule init role <ロール名>
今回は下記のコマンドを実行しました。
molecule init role sample
sampleロールが生成されます。
※Moleculeを動かしてみることが目的なので、とってもイージーなPlaybookです。
testと記載されたファイルを/tmp/test.txtに配置するだけのPlaybookです。
- ./roles/sample/tasks/main.yml
--- - name: copy test file copy: src: test.txt dest: /tmp/test.txt
- ./roles/sample/files/test.txt
test
【参考】既存のロールにmolecule設定ファイルを追加する場合
ロールのディレクトリ配下に移動して、下記のコマンドを実行します。
molecule init scenario -r <ロール名>
ちなみに1階層上(roles直下)実行すると、以下のようなエラーが出ます。
ロールのディレクトリ直下で実行しましょう。
ERROR: The role '<ロール名>' not found. Please choose the proper role name.
Ansibleロールを単体テストするPlaybookを作成
molecule.ymlの編集
単体テストコードを作成する前に、moleculeの動作設定を確認しておきましょう。
- ./roles/sample/molecule/default/molecule.yml
--- dependency: name: galaxy driver: name: docker lint: ansible-lint platforms: - name: instance image: docker.io/pycontribs/centos:8 pre_build_image: true provisioner: name: ansible verifier: name: ansible
今回デフォルトから変更した点は、以下の点です。
ansible-lintによる静的解析を実行したいので下記の2行を追記しました。
lint: ansible-lint
lintの定義はコマンドさながらに定義できるので、
例えばansible-lintで無視させたいルールがあるとしたら、
下記のように定義すればOKです。
lint: ansible-lint -x 201
※201のルールを無視させています(参考)
デフォルトから変えていませんが、
前提条件で謳っていた下記の項目はmolecule.ymlの定義に依存しています。
- PlaybookのテストはCentos8のDockerコンテナで実行させる
driver: name: docker
platforms: - name: instance image: docker.io/pycontribs/centos:8 pre_build_image: true
- テストコードもPlaybookで記述
verifier: name: ansible
ほかにもansibleオプションを定義できたり、
テストをtestinfraというpython製のツールで実行できたり、
いろいろ設定できるようです。
詳細は公式ドキュメントをご確認ください。
テストコードの作成
moleculeコマンドで生成されるverify.ymlにテスト処理を定義します。
- ./roles/sample/molecule/default/verify.yml
--- - name: Verify hosts: all tasks: - name: Verify with wait_for module wait_for: path: /tmp/test.txt search_regex: "{{ item }}" timeout: 5 with_items: - "test" - name: Verify with command module Execution command: cat /tmp/test.txt register: command_result ignore_errors: true changed_when: false - name: Verify with command module Check Result assert: that: - "'test' in command_result.stdout"
テスト対象のPlaybookが、
testと記載されたファイルを/tmp/test.txtに配置するだけのPlaybook
なので、
配置したtest.txtにtestという文字列が含まれているか
を確認するPlaybookを作成しました。
下記の2種類の確認方法(やっていることはほぼ同じ)を仕込んでみました。
- wait_forモジュールを使用した確認
- Verify with wait_for module
- commandモジュールを使用した確認
- Verify with command module Execution
- Verify with command module Check Result
※冪等性の試験とかもいつか試したいと思います。
GitにPushする
作成した./roles/sampleをGitリポジトリsample_playbookにpushします。
Jenkinsジョブ実行
Jenkinsには以下の設定がしてある前提です。
- 認証情報に
git-credentialを登録している - Jenkinsスレーブに
slave-nodeというラベルを付与している
Jenkinsの新規ジョブ作成から下記の設定のジョブを作成します。
- ジョブ名:Execute_Molecule
- 種類:パイプライン
ビルドのパラメータ化にチェックを入れ、下記のパラメータを設定します。
| パラメータ名 | 型 | デフォルト値 |
|---|---|---|
| GIT_REPOSITORY_PATH | 文字列 | http://127.0.0.1/gitlab/sample_playbook.git |
| ROLE_PATH | テキスト | sample |
pipeline{
agent{
node{
label 'slave-node'
}
}
stages{
stage('Gitクローン'){
steps{
deleteDir()
git(
url: GIT_REPOSITORY_PATH,
credentialsId: 'git_credential',
branch: 'master'
)
}
}
stage('molecule実行'){
steps{
script{
def roles = ROLE_LIST.split("\n")
sh "mkdir logs"
roles.each{ role ->
echo """Start Testing ${role}"""
dir("${WORKSPACE}/roles/${role}"){
def result = sh (
script: "/usr/local/bin/molecule test",
returnStdout: true
)
echo "${result}"
writeFile(
file: "${WORkSPACE}/logs/${role}_molecule.log",
text: "${result}"
)
}
}
}
}
}
stage('Archive artifacts'){
steps{
archiveArtifacts "logs/*"
}
}
}
}
上記のジョブを作成し、
下記のパラメータを設定して実行してみてください。
| パラメータ | 値 |
|---|---|
| GIT_REPOSITORY_PATH | Gitのリポジトリパス |
| ROLE_LIST | Moleculeを実行したいロール名(改行区切りで複数指定可) |
moleculeテスト結果出力
ジョブに定義したパイプラインを見れば気づくと思いますが、
moleculeの実行結果を<ロール名>_molecule.logに出力し、
Jenkinsジョブの成果物として保存されます。
こんなログが出てくるかと思います。
--> Test matrix
└── default
├── dependency
├── lint
├── cleanup
├── destroy
├── syntax
├── create
├── prepare
├── converge
├── idempotence
├── side_effect
├── verify
├── cleanup
└── destroy
--> Scenario: 'default'
--> Action: 'dependency'
Skipping, missing the requirements file.
Skipping, missing the requirements file.
--> Scenario: 'default'
--> Action: 'lint'
--> Executing: ansible-lint
--> Scenario: 'default'
--> Action: 'cleanup'
Skipping, cleanup playbook not configured.
--> Scenario: 'default'
--> Action: 'destroy'
--> Sanity checks: 'docker'
PLAY [Destroy] *****************************************************************
TASK [Destroy molecule instance(s)] ********************************************
changed: [localhost] => (item=instance)
TASK [Wait for instance(s) deletion to complete] *******************************
ok: [localhost] => (item=None)
ok: [localhost]
TASK [Delete docker network(s)] ************************************************
PLAY RECAP *********************************************************************
localhost : ok=2 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
--> Scenario: 'default'
--> Action: 'syntax'
playbook: /home/jenkins/agent/workspace/Execute_Molecule/ansible_playbooks/sample/molecule/default/converge.yml
--> Scenario: 'default'
--> Action: 'create'
PLAY [Create] ******************************************************************
TASK [Log into a Docker registry] **********************************************
skipping: [localhost] => (item=None)
TASK [Check presence of custom Dockerfiles] ************************************
ok: [localhost] => (item=None)
ok: [localhost]
TASK [Create Dockerfiles from image names] *************************************
skipping: [localhost] => (item=None)
TASK [Discover local Docker images] ********************************************
ok: [localhost] => (item=None)
ok: [localhost]
TASK [Build an Ansible compatible image (new)] *********************************
skipping: [localhost] => (item=molecule_local/docker.io/pycontribs/centos:8)
TASK [Create docker network(s)] ************************************************
TASK [Determine the CMD directives] ********************************************
ok: [localhost] => (item=None)
ok: [localhost]
TASK [Create molecule instance(s)] *********************************************
changed: [localhost] => (item=instance)
TASK [Wait for instance(s) creation to complete] *******************************
FAILED - RETRYING: Wait for instance(s) creation to complete (300 retries left).
changed: [localhost] => (item=None)
changed: [localhost]
PLAY RECAP *********************************************************************
localhost : ok=5 changed=2 unreachable=0 failed=0 skipped=4 rescued=0 ignored=0
--> Scenario: 'default'
--> Action: 'prepare'
Skipping, prepare playbook not configured.
--> Scenario: 'default'
--> Action: 'converge'
PLAY [Converge] ****************************************************************
TASK [Gathering Facts] *********************************************************
ok: [instance]
TASK [Include sample] **********************************************************
TASK [sample : copy test file] ****************************************************
changed: [instance]
PLAY RECAP *********************************************************************
instance : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
--> Scenario: 'default'
--> Action: 'idempotence'
Idempotence completed successfully.
--> Scenario: 'default'
--> Action: 'side_effect'
Skipping, side effect playbook not configured.
--> Scenario: 'default'
--> Action: 'verify'
--> Running Ansible Verifier
PLAY [Verify] ******************************************************************
TASK [Gathering Facts] *********************************************************
ok: [instance]
TASK [Verify with wait_for module] *********************************************
ok: [instance] => (item=test)
TASK [Verify with command module Execution] ************************************
ok: [instance]
TASK [Verify with command module Check Result] *********************************
ok: [instance] => {
"changed": false,
"msg": "All assertions passed"
}
PLAY RECAP *********************************************************************
instance : ok=4 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Verifier completed successfully.
--> Scenario: 'default'
--> Action: 'cleanup'
Skipping, cleanup playbook not configured.
--> Scenario: 'default'
--> Action: 'destroy'
PLAY [Destroy] *****************************************************************
TASK [Destroy molecule instance(s)] ********************************************
changed: [localhost] => (item=instance)
TASK [Wait for instance(s) deletion to complete] *******************************
changed: [localhost] => (item=None)
changed: [localhost]
TASK [Delete docker network(s)] ************************************************
PLAY RECAP *********************************************************************
localhost : ok=2 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
--> Pruning extra files from scenario ephemeral directory
上記、クリアしている例ですが、
何かしらテストがNGになると、
molecule testコマンドのリターンコードが0以外になるので、
ジョブが異常終了します。
おわりに
PlaybookもCIしていくって考え、大事だとおもいます。
業務で触っているということもあり、Jenkinsに乗せてみましたが、
Github actionやGitLab runnerを使用したインフラCIもいつか試したいと思います。
参考
【Kubernetes】CentOS8環境にMinikubeをインストール
はじめに
大学生から使っていたポンコツPC(Windows)にCentOS8を入れ、
勉強用マシンとして再生させました。
Kubernetes勉強用にMinikubeをインストールしたので、
構築メモを残しておこうと思います。
とりあえずローカルからダッシュボードが見れるところまでできました。
環境
| 項目 | 値 |
|---|---|
| OS | CentOS8.2.2004 |
| Minikube | v1.12.0 |
| Kubernetes | v1.18.3 |
| Docker | 19.03.12 |
構築手順
Dockerをインストール
qiita.com 上記の記事を参考にしました。
# dnf update -y # dnf repolist repo id repo の名前 AppStream CentOS-8 - AppStream BaseOS CentOS-8 - Base extras CentOS-8 - Extras # dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo repo の追加: https://download.docker.com/linux/centos/docker-ce.repo # dnf repolist repo id repo の名前 AppStream CentOS-8 - AppStream BaseOS CentOS-8 - Base docker-ce-stable Docker CE Stable - x86_64 extras CentOS-8 - Extras
そのままdnf -y install docker-ce docker-ce-cli containerd.ioを実行すると、
参考記事と同様にcontainerd.ioのバージョンについてのエラーが出てきます。
CentOS8ではcontainerd.io >= 1.2.2-3がまだ提供されていないからのようです。
rpmを落としてきてインストールしておきます。
前述のコマンドに-nobestオプションをつけてもいけるようです。
# wget https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.2.2-3.3.el7.x86_64.rpm
--2020-07-12 06:09:22-- https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.2.2-3.3.el7.x86_64.rpm
download.docker.com (download.docker.com) をDNSに問いあわせています... 99.86.193.61, 99.86.193.20, 99.86.193.109, ...
download.docker.com (download.docker.com)|99.86.193.61|:443 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 23159364 (22M) [application/x-redhat-package-manager]
`containerd.io-1.2.2-3.3.el7.x86_64.rpm' に保存中
containerd.io-1.2.2 100%[===================>] 22.09M 2.11MB/s 時間 10s
2020-07-12 06:09:33 (2.15 MB/s) - `containerd.io-1.2.2-3.3.el7.x86_64.rpm' へ保存完了 [23159364/23159364]
# dnf install containerd.io-1.2.2-3.3.el7.x86_64.rpm
メタデータの期限切れの最終確認: 0:01:25 時間前の 2020年07月12日 06時08分57秒 に実施しました。
依存関係が解決しました。
================================================================================
パッケージ Arch バージョン リポジトリー サイズ
================================================================================
インストール中:
containerd.io x86_64 1.2.2-3.3.el7 @commandline 22 M
置き換え runc.x86_64 1.0.0-65.rc10.module_el8.2.0+305+5e198a41
トランザクションの概要
================================================================================
インストール 1 パッケージ
合計サイズ: 22 M
これでよろしいですか? [y/N]: y
パッケージのダウンロード:
トランザクションの確認を実行中
トランザクションの確認に成功しました。
トランザクションのテストを実行中
トランザクションのテストに成功しました。
トランザクションを実行中
準備 : 1/1
インストール中 : containerd.io-1.2.2-3.3.el7.x86_64 1/2
scriptlet の実行中: containerd.io-1.2.2-3.3.el7.x86_64 1/2
廃止 : runc-1.0.0-65.rc10.module_el8.2.0+305+5e198a41.x86_ 2/2
scriptlet の実行中: runc-1.0.0-65.rc10.module_el8.2.0+305+5e198a41.x86_ 2/2
検証 : containerd.io-1.2.2-3.3.el7.x86_64 1/2
検証 : runc-1.0.0-65.rc10.module_el8.2.0+305+5e198a41.x86_ 2/2
Installed products updated.
インストール済み:
containerd.io-1.2.2-3.3.el7.x86_64
完了しました!
# dnf install -y docker-ce docker-ce-cli
メタデータの期限切れの最終確認: 0:01:46 時間前の 2020年07月12日 06時08分57秒 に実施しました。
依存関係が解決しました。
================================================================================
パッケージ Arch バージョン リポジトリー サイズ
================================================================================
インストール中:
docker-ce x86_64 3:19.03.12-3.el7 docker-ce-stable 24 M
docker-ce-cli x86_64 1:19.03.12-3.el7 docker-ce-stable 38 M
依存関係のインストール中:
libcgroup x86_64 0.41-19.el8 BaseOS 70 k
トランザクションの概要
================================================================================
インストール 3 パッケージ
ダウンロードサイズの合計: 62 M
インストール済みのサイズ: 263 M
パッケージのダウンロード:
(1/3): libcgroup-0.41-19.el8.x86_64.rpm 307 kB/s | 70 kB 00:00
(2/3): docker-ce-19.03.12-3.el7.x86_64.rpm 1.4 MB/s | 24 MB 00:17
(3/3): docker-ce-cli-19.03.12-3.el7.x86_64.rpm 1.2 MB/s | 38 MB 00:32
--------------------------------------------------------------------------------
合計 1.9 MB/s | 62 MB 00:33
警告: /var/cache/dnf/docker-ce-stable-091d8a9c23201250/packages/docker-ce-19.03.12-3.el7.x86_64.rpm: ヘッダー V4 RSA/SHA512 Signature、鍵 ID 621e9f35: NOKEY
Docker CE Stable - x86_64 5.8 kB/s | 1.6 kB 00:00
GPG 鍵 0x621E9F35 をインポート中:
Userid : "Docker Release (CE rpm) <docker@docker.com>"
Fingerprint: 060A 61C5 1B55 8A7F 742B 77AA C52F EB6B 621E 9F35
From : https://download.docker.com/linux/centos/gpg
鍵のインポートに成功しました
トランザクションの確認を実行中
トランザクションの確認に成功しました。
トランザクションのテストを実行中
トランザクションのテストに成功しました。
トランザクションを実行中
準備 : 1/1
インストール中 : docker-ce-cli-1:19.03.12-3.el7.x86_64 1/3
scriptlet の実行中: docker-ce-cli-1:19.03.12-3.el7.x86_64 1/3
scriptlet の実行中: libcgroup-0.41-19.el8.x86_64 2/3
インストール中 : libcgroup-0.41-19.el8.x86_64 2/3
scriptlet の実行中: libcgroup-0.41-19.el8.x86_64 2/3
インストール中 : docker-ce-3:19.03.12-3.el7.x86_64 3/3
scriptlet の実行中: docker-ce-3:19.03.12-3.el7.x86_64 3/3
検証 : libcgroup-0.41-19.el8.x86_64 1/3
検証 : docker-ce-3:19.03.12-3.el7.x86_64 2/3
検証 : docker-ce-cli-1:19.03.12-3.el7.x86_64 3/3
Installed products updated.
インストール済み:
docker-ce-3:19.03.12-3.el7.x86_64 docker-ce-cli-1:19.03.12-3.el7.x86_64
libcgroup-0.41-19.el8.x86_64
完了しました!
Minikubeのインストール
Minikubeをインストールします。
# curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 54.9M 100 54.9M 0 0 2783k 0 0:00:20 0:00:20 --:--:-- 3640k
kube-ctlをインストールします。
# curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl && chmod +x kubectl && sudo mv kubectl /usr/local/bin/
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 41.9M 100 41.9M 0 0 1708k 0 0:00:25 0:00:25 --:--:-- 1824k
環境変数を/etc/profileに定義します。
# vi /etc/profile
下記の定義を追加します。
export MINIKUBE_WANTUPDATENOTIFICATION=false export MINIKUBE_WANTREPORTERRORPROMPT=false export MINIKUBE_HOME=/root export CHANGE_MINIKUBE_NONE_USER=true export KUBECONFIG=/root/.kube/config
/root/.kube/configを作成します。
# mkdir -p /root/.kube || true # touch /root/.kube/config
Minikubeの起動!
# /usr/local/bin/minikube start --vm-driver=none 😄 Centos 8.2.2004 上の minikube v1.12.0 ✨ 設定を元に、 none ドライバを使用します 💣 Sorry, Kubernetes 1.18.3 requires conntrack to be installed in root's path
おや。。。 conntrackがないよと言われたので、インストールします。
# dnf install conntrack メタデータの期限切れの最終確認: 0:07:56 時間前の 2020年07月12日 06時08分57秒 に実施しました。 依存関係が解決しました。 ================================================================================ パッケージ Arch バージョン Repo サイズ ================================================================================ インストール中: conntrack-tools x86_64 1.4.4-10.el8 BaseOS 204 k 依存関係のインストール中: libnetfilter_cthelper x86_64 1.0.0-15.el8 BaseOS 24 k libnetfilter_cttimeout x86_64 1.0.0-11.el8 BaseOS 24 k libnetfilter_queue x86_64 1.0.2-11.el8 BaseOS 30 k トランザクションの概要 ================================================================================ インストール 4 パッケージ ダウンロードサイズの合計: 282 k インストール済みのサイズ: 699 k これでよろしいですか? [y/N]: y パッケージのダウンロード: (1/4): libnetfilter_cttimeout-1.0.0-11.el8.x86_ 80 kB/s | 24 kB 00:00 (2/4): libnetfilter_cthelper-1.0.0-15.el8.x86_6 67 kB/s | 24 kB 00:00 (3/4): libnetfilter_queue-1.0.2-11.el8.x86_64.r 100 kB/s | 30 kB 00:00 (4/4): conntrack-tools-1.4.4-10.el8.x86_64.rpm 314 kB/s | 204 kB 00:00 -------------------------------------------------------------------------------- 合計 189 kB/s | 282 kB 00:01 トランザクションの確認を実行中 トランザクションの確認に成功しました。 トランザクションのテストを実行中 トランザクションのテストに成功しました。 トランザクションを実行中 準備 : 1/1 インストール中 : libnetfilter_queue-1.0.2-11.el8.x86_64 1/4 scriptlet の実行中: libnetfilter_queue-1.0.2-11.el8.x86_64 1/4 インストール中 : libnetfilter_cttimeout-1.0.0-11.el8.x86_64 2/4 scriptlet の実行中: libnetfilter_cttimeout-1.0.0-11.el8.x86_64 2/4 インストール中 : libnetfilter_cthelper-1.0.0-15.el8.x86_64 3/4 scriptlet の実行中: libnetfilter_cthelper-1.0.0-15.el8.x86_64 3/4 インストール中 : conntrack-tools-1.4.4-10.el8.x86_64 4/4 scriptlet の実行中: conntrack-tools-1.4.4-10.el8.x86_64 4/4 検証 : conntrack-tools-1.4.4-10.el8.x86_64 1/4 検証 : libnetfilter_cthelper-1.0.0-15.el8.x86_64 2/4 検証 : libnetfilter_cttimeout-1.0.0-11.el8.x86_64 3/4 検証 : libnetfilter_queue-1.0.2-11.el8.x86_64 4/4 Installed products updated. インストール済み: conntrack-tools-1.4.4-10.el8.x86_64 libnetfilter_cthelper-1.0.0-15.el8.x86_64 libnetfilter_cttimeout-1.0.0-11.el8.x86_64 libnetfilter_queue-1.0.2-11.el8.x86_64 完了しました!
これでOKかと、、 Minikubeの起動リトライ!
# /usr/local/bin/minikube start --vm-driver=none
😄 Centos 8.2.2004 上の minikube v1.12.0
✨ 設定を元に、 none ドライバを使用します
👍 Starting control plane node minikube in cluster minikube
🤹 Running on localhost (CPUs=2, Memory=3659MB, Disk=51175MB) ...
ℹ️ OS は CentOS Linux 8 (Core) です。
🐳 Docker 19.03.12 で Kubernetes v1.18.3 を準備しています...
> kubelet.sha256: 65 B / 65 B [--------------------------] 100.00% ? p/s 0s
> kubeadm.sha256: 65 B / 65 B [--------------------------] 100.00% ? p/s 0s
> kubectl.sha256: 65 B / 65 B [--------------------------] 100.00% ? p/s 0s
> kubeadm: 37.97 MiB / 37.97 MiB [---------------] 100.00% 2.52 MiB p/s 15s
> kubectl: 41.99 MiB / 41.99 MiB [-------------] 100.00% 956.85 KiB p/s 45s
> kubelet: 108.04 MiB / 108.04 MiB [-------------] 100.00% 1.99 MiB p/s 54s
💥 初期化が失敗しました。再施行します。 run: /bin/bash -c "sudo env PATH=/var/lib/minikube/binaries/v1.18.3:$PATH kubeadm init --config /var/tmp/minikube/kubeadm.yaml --ignore-preflight-errors=DirAvailable--etc-kubernetes-manifests,DirAvailable--var-lib-minikube,DirAvailable--var-lib-minikube-etcd,FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml,FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml,FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml,FileAvailable--etc-kubernetes-manifests-etcd.yaml,Port-10250,Swap": exit status 1
stdout:
[init] Using Kubernetes version: v1.18.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/var/lib/minikube/certs"
[certs] Using existing ca certificate authority
[certs] Using existing apiserver certificate and key on disk
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [piyohost localhost] and IPs [192.168.10.3 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [piyohost localhost] and IPs [192.168.10.3 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
stderr:
W0712 06:18:46.402114 63103 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[WARNING Firewalld]: firewalld is active, please ensure ports [8443 10250] are open or your cluster may not function correctly
[WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service'
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING Swap]: running with swap on is not supported. Please disable swap
[WARNING FileExisting-socat]: socat not found in system path
[WARNING Hostname]: hostname "piyohost" could not be reached
[WARNING Hostname]: hostname "piyohost": lookup piyohost on 192.168.10.1:53: no such host
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
W0712 06:21:17.837160 63103 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
W0712 06:21:17.839148 63103 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
上記のエラーはSELinuxを無効にすると解決しました。 (このあと/etc/selinux/config も書き換えておきました。)
# getenforce Enforcing # setenforce 0 # getenforce Permissive
Minikubeの起動リトライ!
# /usr/local/bin/minikube start --vm-driver=none
😄 Centos 8.2.2004 上の minikube v1.12.0
✨ プロフィールを元に、 none ドライバを使用します
👍 Starting control plane node minikube in cluster minikube
🏃 Updating the running none "minikube" bare metal machine ...
ℹ️ OS は CentOS Linux 8 (Core) です。
🐳 Docker 19.03.12 で Kubernetes v1.18.3 を準備しています...
🤦 Unable to restart cluster, will reset it: getting k8s client: client config: client config: context "minikube" does not exist
🤹 Configuring local host environment ...
❗ The 'none' driver is designed for experts who need to integrate with an existing VM
💡 Most users should use the newer 'docker' driver instead, which does not require root!
📘 For more information, see: https://minikube.sigs.k8s.io/docs/reference/drivers/none/
❗ kubectl と minikube の構成は /root に保存されます
❗ kubectl か minikube コマンドを独自のユーザーとして使用するには、そのコマンドの再配置が必要な場合があります。たとえば、独自の設定を上書きするには、以下を実行します
▪ sudo mv /root/.kube /root/.minikube $HOME
▪ sudo chown -R $USER $HOME/.kube $HOME/.minikube
💡 これは環境変数 CHANGE_MINIKUBE_NONE_USER=true を設定して自動的に行うこともできます
🔎 Verifying Kubernetes components...
🌟 Enabled addons: default-storageclass, storage-provisioner
🏄 Done! kubectl is now configured to use "minikube"
無事起動しました。
# minikube status minikube type: Control Plane host: Running kubelet: Running apiserver: Running kubeconfig: Configured
ダッシュボードにアクセス
ダッシュボードを起動します。
minikube dashboard --url & [1] 88067 # 🤔 ダッシュボードの状態を確認しています... 🚀 プロキシを起動しています... 🤔 プロキシの状態を確認しています... http://127.0.0.1:37507/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/

おわりに
とりあえず今日はダッシュボード見て満足して終わります。 podやdeploymentについてはまた次回…